유니온 파인드 알고리즘
유니온 파인드(Union-Find) 알고리즘은 서로소 집합(Disjoint Set Union, DSU) 자료구조를 이용해 원소들이 같은 집합에 속하는지 판별하거나, 두 집합을 하나로 합치는 연산을 효율적으로 처리하는 알고리즘이다.
서로소 집합
여러 개의 집합이 있을 때, 어떤 두 집합도 공통 원소를 갖지 않는 경우를 말함.
즉, 집합끼리 겹치는 부분이 전혀 없는 상태
{1, 2}, {3, 4}, {5, 6}
유니온 파인드 알고리즘 적용 예시
- 그래프 이론 관련
- 최소 신장 트리 (MST) - 크루스칼 알고리즘
- 사이클 판별
- 간선을 하나씩 추가하면서 두 정점이 이미 같은 집합인지 확인(Union) -> 같은 집합이면 사이클 존재
- 연결 요소 찾기
- 그래프에서 분리된 그룹 개수 세기
이렇게 말해도 사실상 와닿지 않으니까 한 마디로 정리해보면, "서로 연결된 덩어리"를 관리할 때 고려해볼 수 있는 알고리즘 이 된다.
유니온 파인드 동작 원리
1. 자기 자신의 부모를 자신으로 초기화하는 make() 함수
2. 특정 원소의 부모를 찾는 find() 함수
3. 원소 a, 원소 b가 속한 집합을 합치는 union() 함수
4. 문제의 조건에 따라서 원소들을 입력받고 union() 진행
유니온 파인드 동작 미리보기
make()

자신의 부모를 자기 자신으로 모두 초기화 해준다.
해당 그림에서는 부모 노드로의 간선 표시를 생략해주었다.
union(1, 2)

1번 원소와 2번 원소를 union 처리 -> 여기서는 임의로 union의 첫 번째 매개변수에 두 번째 매개변수를 편입시켰음.
union(3, 4)
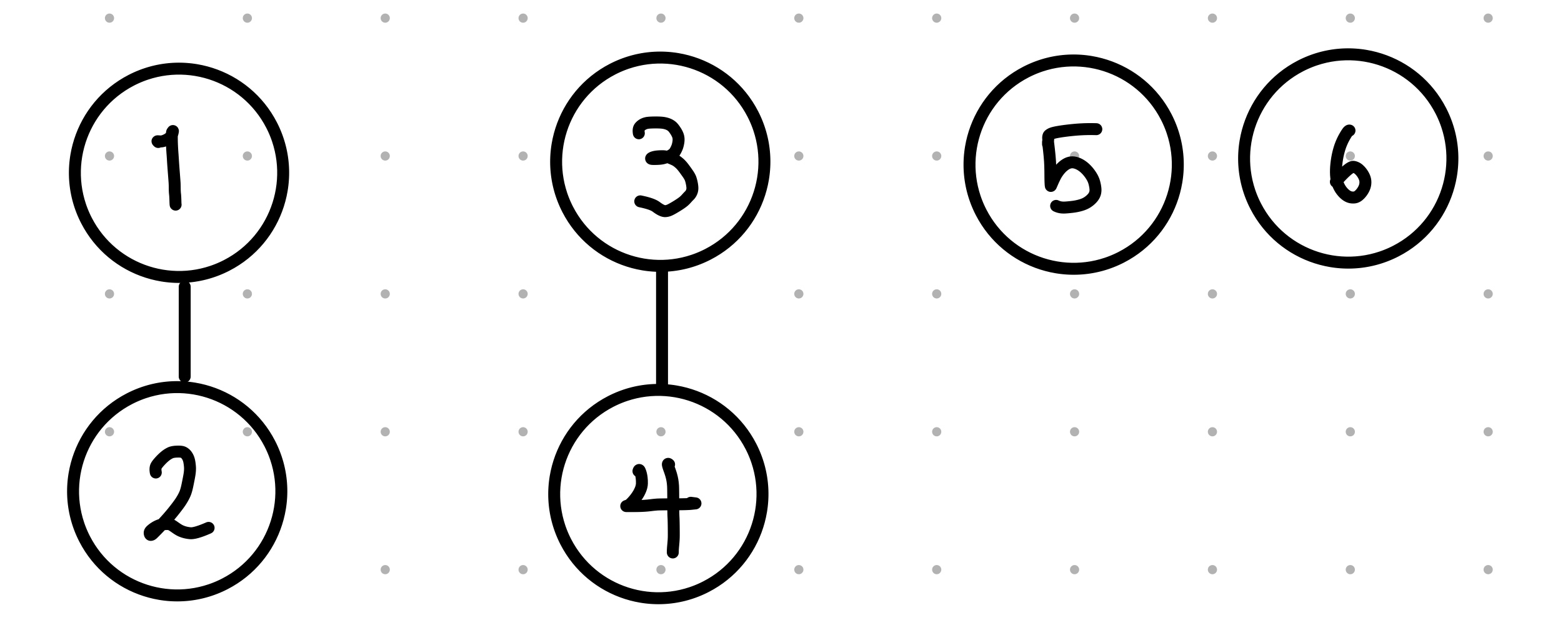
3번 원소와 4번 원소를 union 처리
union(2, 3)
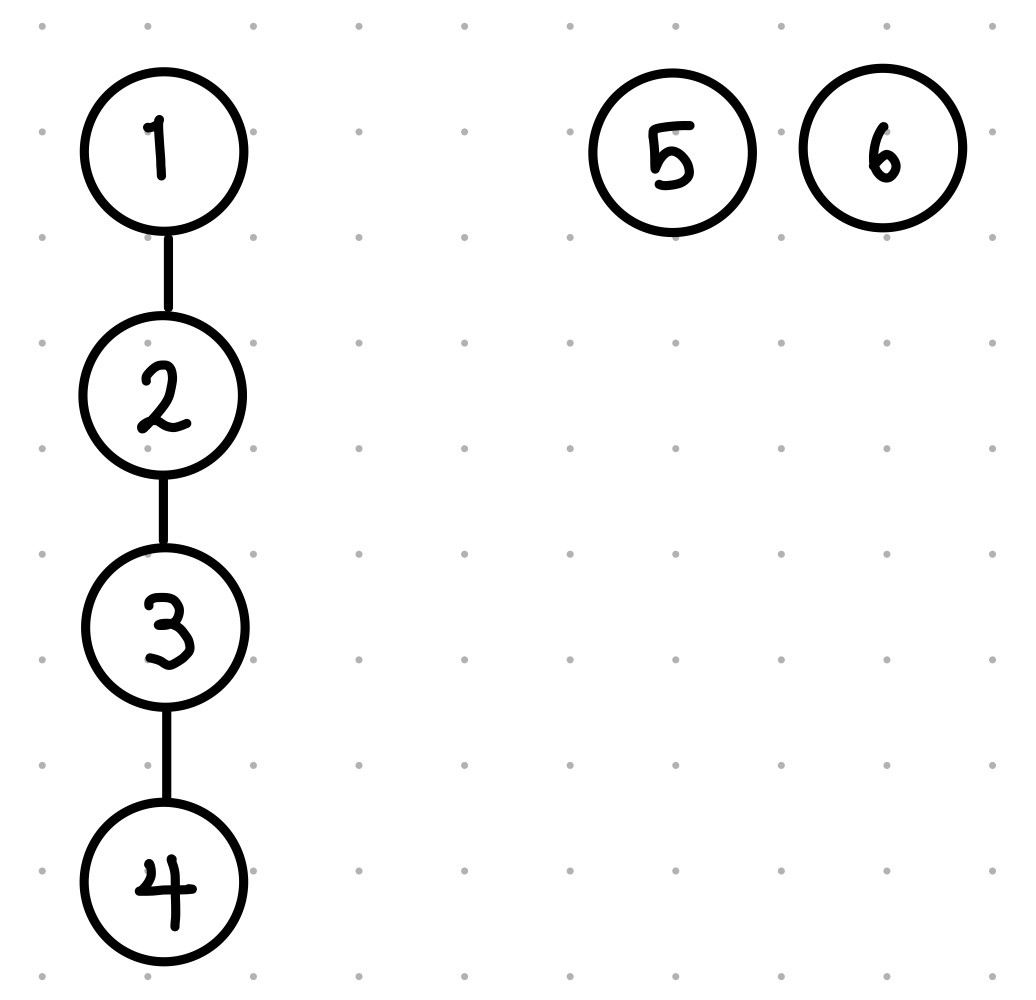
1->3, 3->4 5, 6 과 같은 원소 집합이 있는 상태에서
2번 원소와 3번 원소를 union 해주면 위 그림과 같은 모양이 된다고 생각하면 됨.
유니온 파인드 최적화 방법
find(4) (경로 압축)

유니온 파인드 알고리즘은 트리의 구조가 중요한 것이 아니라 특정 집합에 속했냐 속하지 않았느냐, 어느 집합에 속했느냐와 같이 집합의 관점에서 접근해야 함.
따라서 find() 연산을 실행했을 때, 해당 노드와 연결된 모든 노드들을 일종의 평탄화 작업을 해준다면 다음 조회에서는 상수 시간에 조회할 수 있게 된다.
예시에서는 find(4)를 진행했을 때, 어떤 식으로 동작하게 되는지를 간략하게 표현해보았다.
우선, find(4)를 호출하면 parents[4] = find(parent[4])가 반환되게 된다.
이후 재귀를 타고 들어가서 기저 조건을 만날 때까지 부모가 어느 집합에 속했는지를 찾는다.
parents[4] -> 4번이 가리키고 있는 부모 노드
find() -> 어느 집합에 속했는지(누가 루트 노드인지, 누가 제일 높은 부모인지)
find(parent[4]) -> 4번 노드의 부모가 어느 집합에 속했는지 찾음
실행 결과

find(4)를 통해서 4번 노드, 3번 노드, 2번 노드가 평탄화된 것을 알 수 있음.
Union-by-Rank

또 다른 최적화 기법으로는 랭크를 이용한 최적화 방법이 존재한다.
모든 노드의 부모 값을 -1로 초기화 해준다.
이전 코드와 다른 점은 자기 자신을 부모로 초기화 해주었는데, 여기서는 기본 초기값으로 -1을 초기화해준 것.
union(1, 2)

이후 union 연산을 살펴보자.
1번 노드와 2번 노드의 rank는 같기 때문에, 둘 중 하나를 골라서 rank를 1 감소시켜준다.
또한 2번 노드의 부모 값을 1번 노드를 가리키게끔 갱신해준다.
union(1, 3)
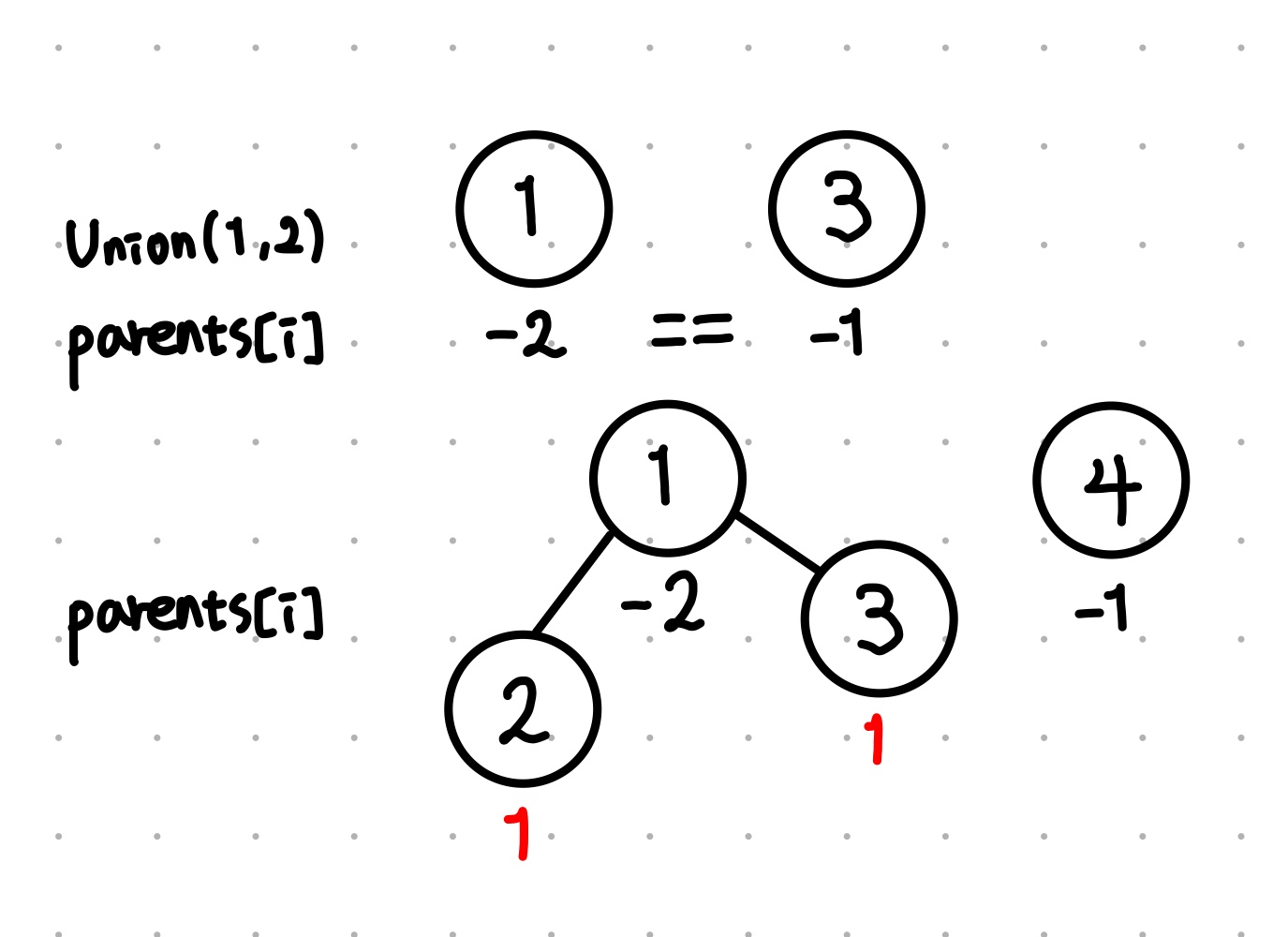
다음으로 union(1, 3) 연산을 살펴보자.
1번 노드의 랭크는 -2, 3번 노드의 rank는 -1인데, 1번 노드의 랭크가 더 높기 때문에 (음수로 커질 수록 커짐)
2번 노드를 그대로 1번 노드의 자식으로 편입시켜주면 된다.
여기서 1번 노드의 rank의 변화는 없다.
rank의 변화가 발생하는 포인트는 union 연산하는 두 노드의 rank 값을 비교해서 만약 두 노드의 rank 값이 같다면 임의로 한 노드의 rank를 증가(단, 음수로 커지게) 시켜주면 된다.
그래서 이게 왜 최적화냐?
유니온 파인드에서 가장 무서운 건 트리가 지팡이처럼 길어지는 편향 이진트리의 모습일 것이다.
- 경로 압축만 있을 때: find를 호출하기 전까지는 트리가 얼마나 깊을지 모름. 만약 100만 개의 노드가 일렬로 연결되어 있다면, 첫 번째 find는 100만 번을 타고 올라가야 함.
- Union-by-Rank가 있을 때: 합칠 때부터 "키 큰 놈이 대장 해라" 규칙을 적용합니다.
위 그림처럼 작은 트리를 큰 트리 밑에 붙이면 전체 트리의 높이가 늘어나지 않습니다. 반대로 큰 트리를 작은 트리 밑에 붙이면? 전체 높이가 확 커지겠죠. 이걸 사전에 차단하는 게 목적입니다.
코드 전문
SWEA 3289 - 서로소 집합
package test;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class SWEA_3289 {
static int n;
static int m;
static int[] parents;
private static void make() {
for (int i = 0; i <= n; i++) {
parents[i] = i; // make set: 자신을 자신의 부모로 초기화(자신이 곧 루트이자 대표자)
}
}
private static int find(int a) { // a가 속한 집합(집합의 대표자) 찾기
if (parents[a] == a) {
return a;
} else {
// return find(parents[a]);
return parents[a] = find(parents[a]); // 패스 압축 적용
}
}
private static boolean union(int a, int b) { // 원소 a, 원소 b가 속한 집합을 합치기
int aRoot = find(a);
int bRoot = find(b);
if (aRoot == bRoot) return false; // 같은 집합이니까 union할 필요 없음
parents[bRoot] = aRoot; // b, a가 아닌, bRoot, aRoot를 사용해야 대표자끼리 연산하는 게 됨.
return true; // union 성공
}
public static void main(String[] args) throws NumberFormatException, IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
int T = Integer.parseInt(br.readLine());
for (int test_case = 1; test_case <= T; test_case++) {
StringTokenizer st = new StringTokenizer(br.readLine());
sb.append("#").append(test_case).append(" ");
n = Integer.parseInt(st.nextToken());
m = Integer.parseInt(st.nextToken());
parents = new int[n + 1];
make();
for (int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
int oper = Integer.parseInt(st.nextToken());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
if (oper == 0) {
union(a, b);
} else {
sb.append(find(a) == find(b) ? 1 : 0);
}
}
sb.append("\n");
}
System.out.print(sb);
}
}최적화가 경로 압축밖에 되지 않은 기본적인 유니온 파인드 알고리즘
SWEA 3124 - 최소 스패닝 트리
package src;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.StringTokenizer;
public class SWEA_3124 {
// Union-Find
public static int[] parents;
public static void make() {
for (int i = 0; i <= V; i++) {
parents[i] = -1; // Union By Rank
}
}
public static int find(int cur) {
if (parents[cur] < 0) return cur; // 값이 -1이면 루트 노드를 의미, -2 이하이면 랭크가 증가한 부모 노드를 의미
return parents[cur] = find(parents[cur]); // 경로 압축
}
public static boolean union(int a, int b) {
int aP = find(a);
int bP = find(b);
// 이미 같은 집합
if (aP == bP) return false;
// 랭크가 서로 다를 때 (b가 더 큰 랭크) -> 왜 스왑? -> 자식으로 만드는 부분을 하나의 코드로 통일
if (parents[aP] > parents[bP]) {
// swap
int temp = aP;
aP = bP;
bP = temp;
}
// 랭크가 서로 같을 때 -> a의 Rank를 증가 (-1, -2, -3 ... 작아질 수록 랭크가 큼)
if (parents[aP] == parents[bP]) {
parents[aP]--;
}
// 기본적으로는 b를 a의 자식으로 만듦.
parents[bP] = aP;
return true; // Union 연산 성공
}
}코드 해설
다른 말 할 필요없이, make, find, union 세 함수만 잘 알고있으면 아무 문제 없이 구현할 수 있다.
'Algorithm' 카테고리의 다른 글
| [JAVA] 최단 거리 알고리즘 - 다익스트라 <Dijkstra> (0) | 2025.09.23 |
|---|---|
| [JAVA] 최소 신장 트리 - Prim 알고리즘 <Minimum Spanning Tree - Prim> (0) | 2025.09.22 |
| [JAVA] 최소 신장 트리 - Kruskal 알고리즘 <Minimum Spanning Tree - Kruskal> (0) | 2025.09.11 |
| [JAVA] 위상 정렬 알고리즘 - 정렬 알고리즘 <Topological Sort> (0) | 2025.09.04 |
| [C/C++]BFS 알고리즘 - 그래프 탐색 알고리즘 <너비 우선 탐색> <Breadth-First Search> (1) | 2023.09.10 |