최소 신장 트리 - MST(Minimum Spanning Tree)
최소 신장 트리의 개념은 아래 글의 초입에 서술되어 있다.
2025.09.11 - [Algorithm] - [JAVA] 최소 신장 트리 - Kruskal 알고리즘
[JAVA] 최소 신장 트리 - Kruskal 알고리즘 <Minimum Spanning Tree - Kruskal>
최소 신장 트리 - MST(Minimum Spanning Tree)최소 신장 트리란, 여러 스패닝 트리 중 간선들의 가중치의 총합이 가장 작은 트리를 이야기한다. 그렇다면 최소 신장 트리를 알려면 신장 트리(Spanning Tree)
bitbard-dongni.tistory.com
Prim 알고리즘
프림 알고리즘의 경우 크루스칼 알고리즘과는 다르게 정점에게 포커싱을 맞춰서 구현한다. 시작 정점부터 가까운 정점마다의 간선을 확인하면서 다소 그리디하게 전개시키는 알고리즘이랄까?
쉽게 생각해보면, 크루스칼 알고리즘에서는 모든 간선의 정보를 오름차순으로 정렬해서 가중치가 가장 작은 간선들을 선택하는 방법이었지만 프림 알고리즘에서는 가까운 간선들 중에서도 특히 더 가까운 정점들을 위주로 선택해가면서 뻗어나가는 알고리즘이란 걸 생각하면 된다.
그림으로 예시를 확인해보자.

자 위와 같은 그래프가 존재한다고 가정해보자.
지금부터 한 단계씩 어떤 동작들이 일어나는지 확인해보면서 프림 알고리즘을 이해해보자.
우선, 임의의 시작 노드로 1번 노드를 선택했다고 생각해보자.
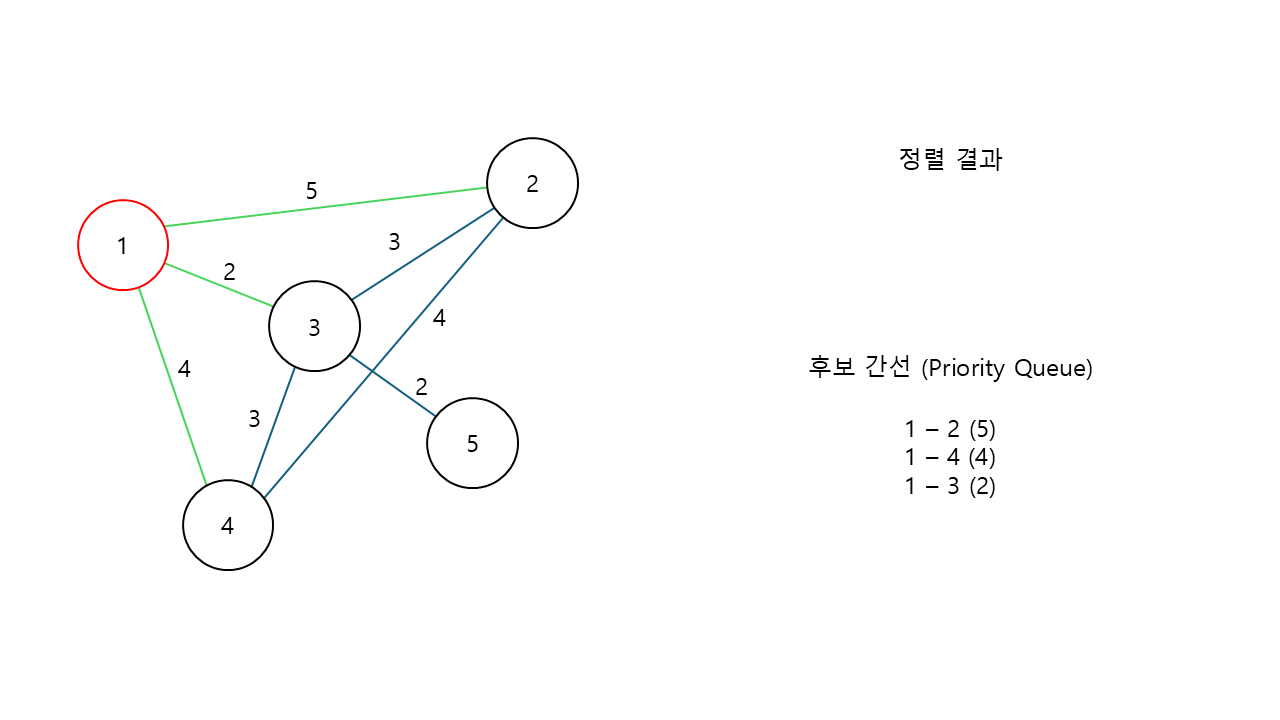
1번 노드를 선택했을 때, 1번 노드와 간선으로 연결된 노드들은 2번, 3번, 4번 노드이다. 이들은 모두 후보 간선에 추가해두자.

후보 간선에서 하나를 꺼내게 되면 자동적으로 현재 노드와 연결 된 간선 중 가장 가중치가 낮은 간선이 꺼내지게 된다.
해당 예시에서는 1번과 3번을 연결하는 간선(가중치 2) 이 선택된다.
이후 정렬 결과에 1번과 3번 노드를 잇는 간선을 추가해준다.
(물론 여기서 임의로 간선을 추가해준건데, 실제로는 노드를 방문처리 한다거나 등의 방식들이 사용된다. 자세한건 후에 설명할 실제 코드 참고)
이후에 1번과 2번, 1번과 4번을 연결하는 간선들은 선택할 수 없게 된다.
왜냐하면 1번 노드와 3번 노드의 방문 여부를 true로 업데이트 해야하기 때문이다.
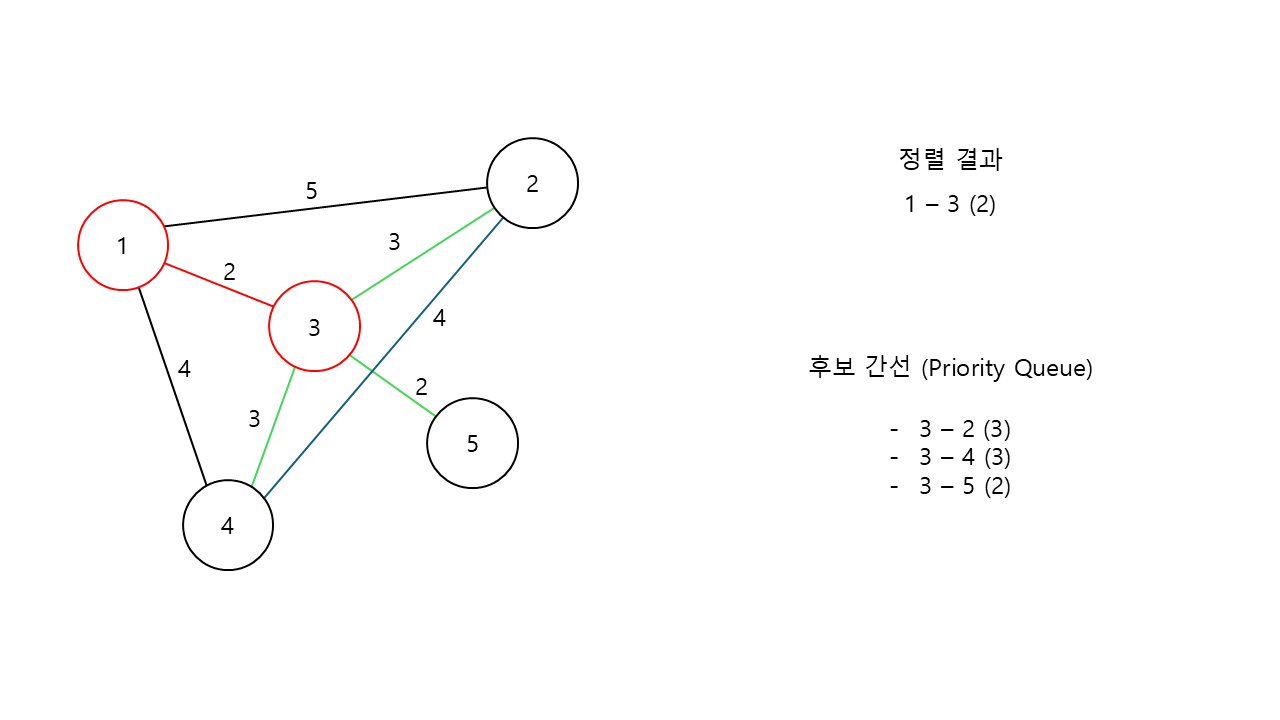
그럼 이제는 3번 노드의 주위를 볼 차례이다. 마찬가지로 3번 노드를 기준으로 후보 간선들을 찾아본다.
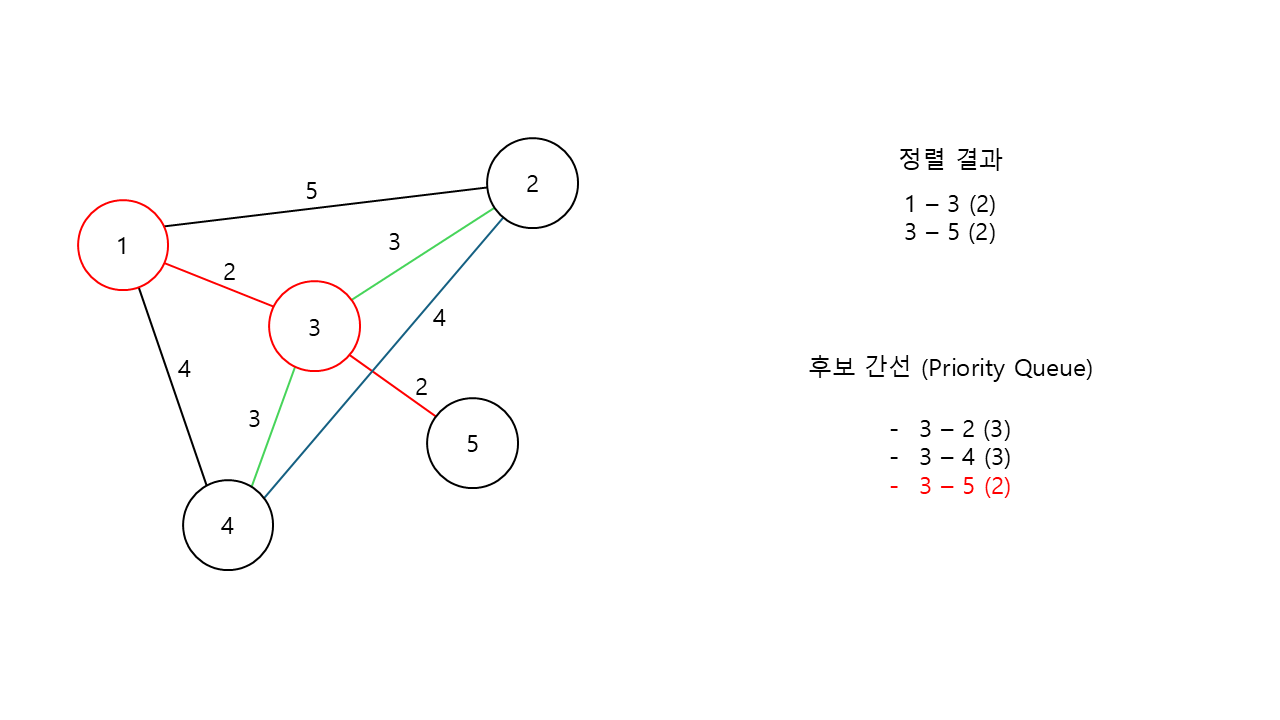
3번 노드의 후보 간선들 중, 가장 가중치가 낮은 3번 노드와 5번 노드를 잇는 간선이 선택된다.
동시에, 정렬 결과에 해당 연결 정보가 저장된다.

이제 5번 노드를 기준으로 확인해보려고 하는데, 후보 간선이 될 수 있는 간선이 아예 존재하지 않는다.
이제는 다시 3번 노드를 기준으로 확인해야 한다.
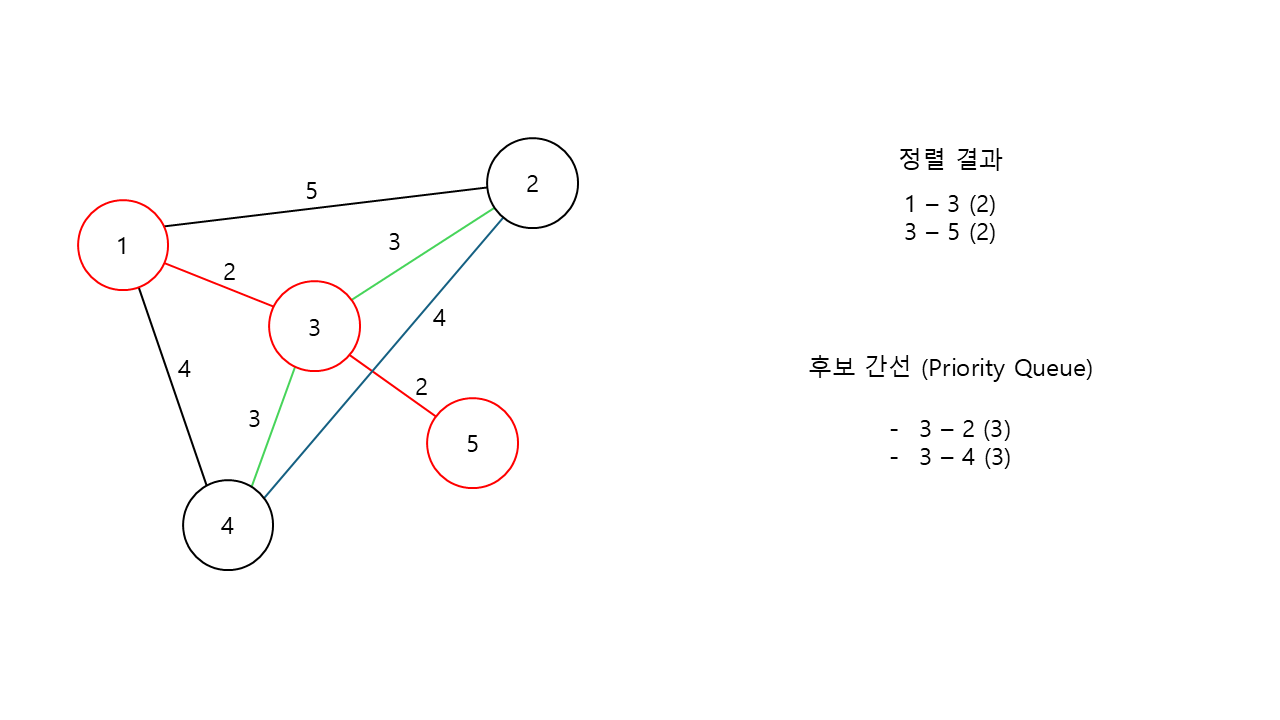
다시 3번 노드를 기준으로, 2번과 4번으로 연결되는 후보 간선이 이제는 2개가 존재한다.
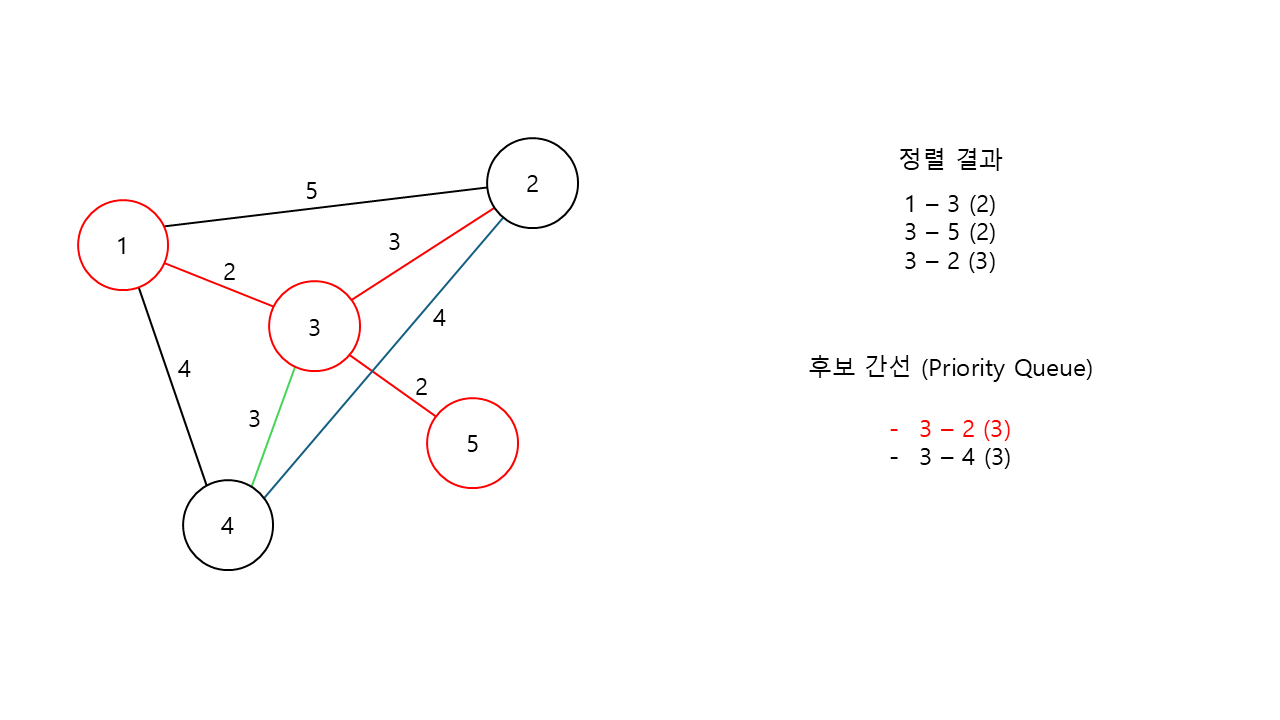
동일한 가중치이기에 임의로 2번 노드로 가는 후보 간선을 선택했다고 가정하고, 정렬 결과에 3번 노드와 2번 노드를 잇는 연결 정보를 추가한다.
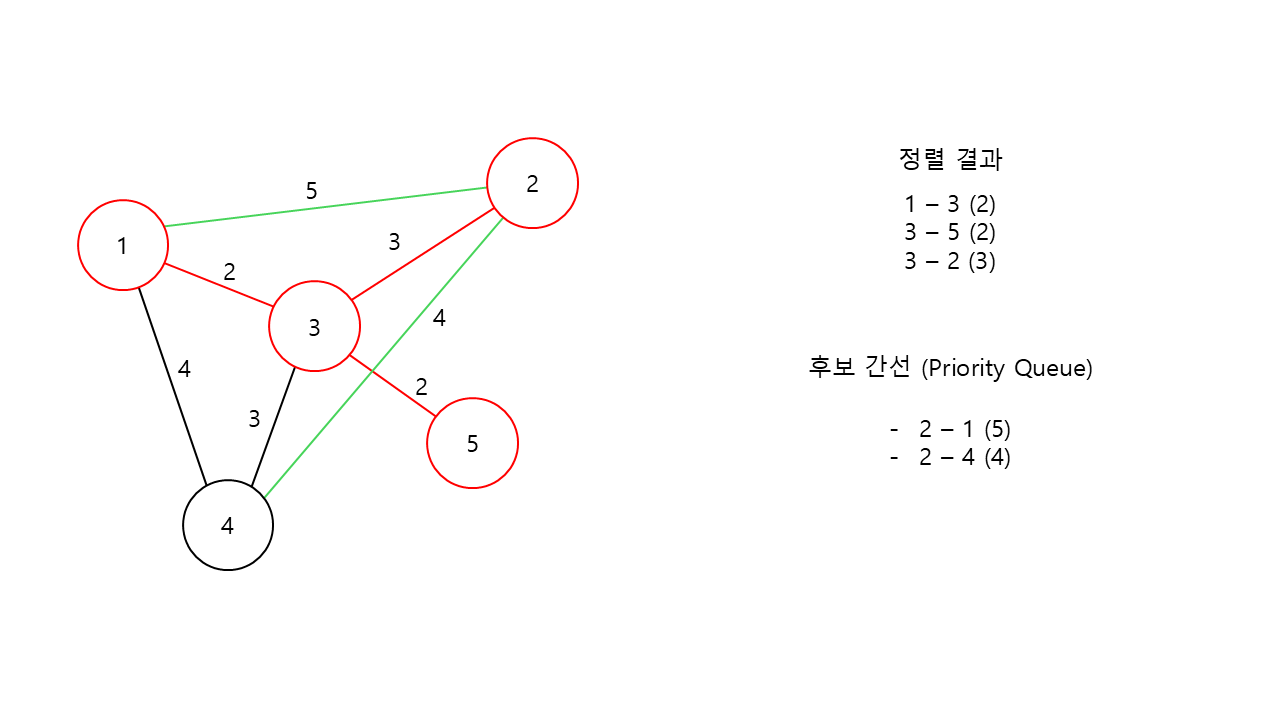
이후, 마찬가지로 2번 노드를 기준으로 후보 간선들을 탐색하고

가장 가중치가 작은 간선을 선택해서 정렬 결과에 추가해준다.

이제 마지막으로 4번 노드를 기준으로 후보 간선들을 탐색해서

정렬 결과에 추가해주면
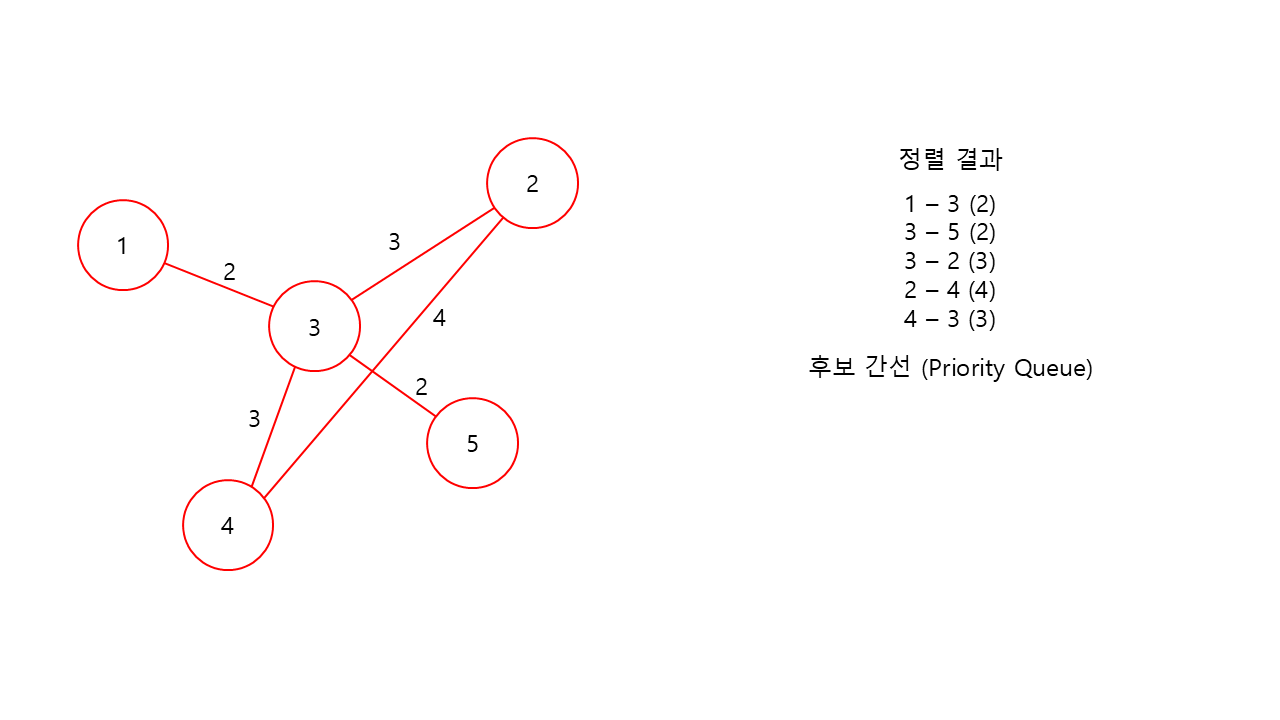
간선의 개수가 (노드의 개수 - 1개)를 만족했기 때문에 여기서 종료되고 프림 알고리즘을 통한 MST 구현을 성공하게 된다.
사실, 엄밀히 따지자면 각 정점을 기준으로 PQ를 생성해서 사용하는 것이 아니기 때문에 이전 간선들의 정보가 모두 저장이 되어있다.
따라서 위와 같은 방법으로 진행된다기 보다는 실제로는 간선을 꺼낼 때, 간선과 연결된 노드가 이미 방문되었다면 해당 간선을 스킵하는 방식으로 구현이 되어있다.
그래서 사실 5번 노드에서 3번 노드로 되돌아간다는 부분에서 약간 이해가 안될 수 있을 것 같다고 생각했다.
결국엔, PQ에 이전까지의 모든 간선 정보가 담겨있는데,
3번 노드에서 5번 노드로 가는 간선을 선택 -> 5번 노드에서는 아무런 간선도 추가하지 않음 -> 3번 노드에서 다른 노드로 가는 간선을 선택
이렇게 5번 노드에서 아무런 간선도 추가하지 않았기 때문에 자연스럽게 다시 이어서 3번 노드에서 다른 노드로 가는 간선을 선택하게 되는 것이다.
물론, 이때 3번 노드에서 다른 노드로 가는 간선보다 더 짧은 가중치의 간선들이 존재한다면 그 간선들이 꺼내져서 선택되겠지만, 실제로 그 간선들의 출발 노드와 도착 노드가 이미 방문 처리 되어있을 것이기 때문에 스킵되고 3번 노드에서 다른 노드로 가는 간선이 선택되게 될 것임은 자명하다.
Prim 알고리즘 동작 원리
1. 인접 리스트에 연결 정보 저장
2. 시작 노드를 기준으로 시작 노드와 연결된 간선을 PQ에 삽입
3. 해당 간선의 도착 노드를 방문 처리
4. 가중치 합 갱신, 선택된 정점 개수 갱신
5. 다음 노드와 연결된 다다음 노드들에 대해서 간선 후보를 PQ에 삽입
6. 모든 정점이 선택 될 때까지 3 ~ 5번 과정 반복
코드 전문
SWEA 3124 - 최소 스패닝 트리
package test;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.PriorityQueue;
import java.util.StringTokenizer;
/**
* @link: https://swexpertacademy.com/main/talk/solvingClub/problemView.do?solveclubId=AZgruskKCQnHBIT9&contestProbId=AV_mSnmKUckDFAWb&probBoxId=AZjkGae6SiPHBIO0+&type=PROBLEM&problemBoxTitle=0826&problemBoxCnt=++3+
* @performance: 2,018 ms, 165,272 kb
* @note:
* - 프림 알고리즘은 기본적으로 무방향 그래프인 걸 명심
* - 진입, 진출 간선 중 하나라도 해당됐으면 정점 자체를 방문처리해야 함
* - 정점도 굳이 간선 배열을 사용할 필요는 없음. -> 인접 리스트를 이용하면 됨
* - 왜 프림은 인접 리스트고 크루스칼은 간선 배열을 썼을까?
* - 크루스칼 알고리즘은 주어진 모든 간선을 오름차순 정렬해주어야 함.
* - 프림 알고리즘은 시작 정점부터 가까운 정점마다의 간선을 차례대로 확인해야 함.
* - 두 알고리즘 모두 MST 알고리즘이지만, 무엇을 중점적으로 보느냐가 다름.
* - 크루스칼은 간선에게 포커싱을, 프림은 정점에게 포커싱을 맞춰서 둘의 구현 방법도 달라짐.
* - 그냥 쉽게 생각해보면, 특정 정점에서 다른 정점들로 뻗어 나갈 때는 인접 행렬 또는 인접 리스트가 떠오르는데
* - 인접 행렬보다 조금 더 공간적으로 활용하기 좋은 인접 리스트를 많이 사용하는 게 정석적임.
* - Q.E.D.
* @timecomplex:
*/
public class SWEA_3124_PRIM {
public static int V;
public static int E;
public static class Node implements Comparable<Node>{
int to;
long weight;
public Node(int to, long weight) {
this.to = to;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
// return this.weight - o.weight;
return Long.compare(this.weight, o.weight);
}
}
static long result;
static boolean[] visited;
static List<Node>[] graph;
public static void main(String[] args) throws NumberFormatException, IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
StringTokenizer st;
int T = Integer.parseInt(br.readLine());
for (int test_case = 1; test_case <= T; test_case++) {
st = new StringTokenizer(br.readLine());
V = Integer.parseInt(st.nextToken());
E = Integer.parseInt(st.nextToken());
result = 0;
visited = new boolean[V + 1];
// 정점을 저장할 인접 리스트
graph = new ArrayList[V + 1];
for (int i = 1; i <= V; i++) {
graph[i] = new ArrayList<>();
}
// 입력
for (int i = 1; i <= E; i++) {
st = new StringTokenizer(br.readLine());
int f = Integer.parseInt(st.nextToken());
int t = Integer.parseInt(st.nextToken());
int w = Integer.parseInt(st.nextToken());
graph[f].add(new Node(t, w));
graph[t].add(new Node(f, w));
}
long result = prim(1);
sb.append("#").append(test_case).append(" ").append(result).append("\n");
}
System.out.print(sb);
}
private static long prim(int start) {
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.add(new Node(start, 0)); // 시작 노드는 가중치가 0
long sum = 0;
long cnt = 0;
while(!pq.isEmpty()) {
Node cur = pq.poll();
if (visited[cur.to]) continue;
visited[cur.to] = true;
sum += cur.weight;
cnt++;
if (cnt == V) break;
for (Node next : graph[cur.to]) {
if (!visited[next.to]) {
pq.add(next);
}
}
}
return sum;
}
}
코드 해설
private static long prim(int start) {
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.add(new Node(start, 0)); // 시작 노드는 가중치가 0
long sum = 0;
long cnt = 0;
while(!pq.isEmpty()) {
Node cur = pq.poll();
if (visited[cur.to]) continue;
visited[cur.to] = true;
sum += cur.weight;
cnt++;
if (cnt == V) break;
for (Node next : graph[cur.to]) {
if (!visited[next.to]) {
pq.add(next);
}
}
}
return sum;
}
PriorityQueue<Node> pq = new PriorityQueue<>();
- 최소 가중치 간선을 항상 꺼낼 수 있도록 우선순위 큐(PQ)를 준비
pq.add(new Node(start, 0)); // 시작 노드는 가중치가 0
- 시작 정점을 MST에 포함시키기 위해 가중치 0으로 PQ에 삽입
- 이렇게 하면 첫 단계에서 자동으로 시작 정점이 선택되게 됨
while(!pq.isEmpty()) {
- 큐가 빌 때까지 반복하면서 MST를 확장
Node cur = pq.poll();
- 현재까지 후보 간선 중 최소 가중치를 가진 간선을 꺼냄
if (visited[cur.to]) continue;
- 꺼낸 간선이 이미 MST에 포함된 정점(이전에 이미 연결된 노드 정보)으로 향하면 무시
- 중복 방문이나 사이클 생성을 막는 역할
visited[cur.to] = true;
- 새로 선택된 정점을 MST에 포함시키고 방문 처리
sum += cur.weight;
cnt++;- 해당 간선의 가중치를 가중치 총합에 합산
- 선택된 정점의 개수(cnt)를 증가시킴
if (cnt == V) break;
- 모든 정점이 MST에 포함되었다면 MST 완성 (종료 조건)
for (Node next : graph[cur.to]) {
if (!visited[next.to]) {
pq.add(next);
}
}
- 현재 정점에서 갈 수 있는 모든 간선을 확인
- 아직 MST에 포함되지 않은 정점으로 향하는 간선만 PQ에 넣어 후보 간선으로 관리
'Algorithm' 카테고리의 다른 글
| [JAVA] 최단 거리 알고리즘 - 다익스트라 <Dijkstra> (0) | 2025.09.23 |
|---|---|
| [JAVA] 최소 신장 트리 - Kruskal 알고리즘 <Minimum Spanning Tree - Kruskal> (0) | 2025.09.11 |
| [JAVA] 유니온 파인드 알고리즘 <Disjoint Set> (0) | 2025.09.05 |
| [JAVA] 위상 정렬 알고리즘 - 정렬 알고리즘 <Topological Sort> (0) | 2025.09.04 |
| [C/C++]BFS 알고리즘 - 그래프 탐색 알고리즘 <너비 우선 탐색> <Breadth-First Search> (1) | 2023.09.10 |